Java 面试题
一、Java基础
1.JDK 和 JRE 有什么区别?
- JDK:java开发工具包,提供了java的开发环境和运行环境。
- JRE:java的运行环境,为java的运行提供了所需环境。
2.== 和 equals 的区别是什么?
== 解读
对于基本类型和引用类型 == 的作用效果是不同的:
- 基本类型:比较的是值是否相同。
- 引用类型:比较的是引用是否相同。
代码示例:
1 | String x = "string"; |
代码解读:
- 因为 x 和 y 指向的是一个引用(指向的都是常量池中的string),所以 == 也是true。
- 因为 new String()方法是重新开辟了内存空间所有 == 的结果为false。
- equals比较的一直都是值所以一直都是true。
equals解读
equals 本质上就是 ==,只不过 String 和 Integer 等重写了 equals 方法,把它变成了值比较。
总结:== 对于基本类型是值比较,对于引用类型是引用比较;而 equals 默认情况下是引用比较。只是很多类重写了 equals 方法。比如 String、Integer 等把它重写成了值比较。
3.两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
不对,两个对象的 hashCode()相同,equals()不一定true。
原因:在散列表中,hashCode()相等,即两个键值对的哈希值相等,然而哈希值相等,并不一定能得出键值对相等。
4.final 在 java 中有什么作用?
- final 修饰的类叫最终类,不能被继承。
- final 修饰的方法不能被重写。
- final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
5.java 中的 Math.round(-1.5) 等于多少?
等于 -1,Math.round() 就是加 0.5 并向下取整。
6.String 属于基础的数据类型吗?
String 不属于基础类型,而属于对象。
基础类型有 8 中:byte、short、int、long、float、double、boolean、char。
7.java 中操作字符串都有哪些类?它们之间有什么区别?
操作字符串的类有:String、StringBuffer、StringBuilder
区别:
- String 声明的是不可变对象,每次操作都会生成新的 String 对象,然后将指针指向新的 String 对象,而 StringBuffer、StringBuilder 可以再原有对象的基础上进行操作。
- StringBuffer 是线程安全的,StringBuilder 相反。
8.String str = “i” 与 String str = new String(“i”) 一样吗?
不一样。
原因:String str = “i” 是被 java 虚拟机分配到常量池中,而 String str = new String(“i”) 是被分配到堆内存中。
9.如何将字符串反转
- 使用 StringBuffer 或者StringBuilder 的 reverse() 方法。
示例代码:
1 | String str = "abc"; |
- 使用 String 的 charAt() 方法,将字符串从后向前取出,存入到 StringBuffer 或者 StringBuilder 中,再转为 String。
示例代码:
1 | String str = "abc"; |
10.String类的常用方法都有哪些?
- indeOf() 返回指定字符的索
- charAt() 返回指定索引的字符
- replace() 字符串替换
- trim() 去除两端的空白
- split() 分割字符串,返回一个分割后的字符串数组
- getBytes() 返回字符串的byte类型数组
- substring() 截取字符串
- length() 返回字符串长度
- equals() 比较字符串
- toLowerCase() 将字符串转为小写字母
- toUpperCase() 将字符串转为大写字母
11.什么是抽象?什么是多态?
抽象:抽象是对具体对象进行提炼,提取对象的同类型的 共性特征 的过程
多态:多态就是多个对象对一个行为的不同响应/多态 是 对象本身具备的不同状态
自我感觉 “抽象” 和 “多态” 很像
12.抽象类必须有抽象方法吗?
不是的,抽象类可以没有抽象方法
13.普通类和抽象类有什么区别?
- 普通类不能有抽象方法,抽象类可以有抽象方法。
- 普通类可以直接实例化,抽象类不能直接实例化。
14.抽象类能使用 final 修饰吗?
不能,final 修饰的类不可被继承,而抽象类就是用来继承的。
15.接口和抽象类有什么区别?
- 实现:接口是由 implements 来实现的,抽象类是由 extends 继承的。
- 构造方法:接口没有构造方法,抽象类有构造方法。
- 实现数量:类可以实现多个接口,但是只能继承一个抽象类
个人理解:抽象类就是实现多态的一种方式
16.Java中的 IO 流分为哪几种?
按功能:输入流(input),输出流(output)
按类型:字节流,字符流
字节流:inputStream、outputStream;
字符流:reader、writer;
17.BIO、NIO、AIO有什么区别?
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
- NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
18.files 的常用方法都有哪些?
- File.exists():检查文件路径是否存在?
- File.createFile():创建文件
- File.createDirectory():创建文件夹
- File.delete():删除一个文件或目录
- File.move():移动文件
- File.copy():复制文件
- File.size():查看文件个数
- File.read():读取文件
- File.write():写入文件
19.简述 java 集合中有关有序、无序的区别,并分别列出其中的典型
- 集合的有序、无序是指插入元素时,插入的顺序性,也就是先插入的元素优先放在集合的前面部分。
- ArrayList 有序的、HashMap 无序的
20.简述 spring 的两大特性
Ioc:控制反转,就是将控制权从程序员交由 spring 容器控制
例:class A 中要用到 class B 中的对象,一般情况的情况下是在 A 的代码中 new 一个 B 的对象。而使用到DI注入后,只需要在 A 中声明一个私有化的 B 对象就可以了
aop:面向切面编程,横向扩展,可以通过动态代理的方式来完成一些重复性高的操作。
例:日志,事务,权限等
21.什么是接口?
接口就是定义了一系列方法,主要是告诉我们这个方法是做什么的,但是具体怎么做是由他的实现类完成的。
22.什么是死锁,产生死锁的四个必要条件是什么?
死锁可以理解为:互相不让步,不放弃,同时需要对方的资源。
例:两个以上线程都在等待对方执行完毕才能继续往下执行,这样就造成了无限等待,也就成了死锁
四个必要条件分别是:
- 互斥:一个资源每次只能被一个进程使用
- 保持锁并请求锁:一个进程因请求资源而阻塞时,对已经获取到的资源保持不放
- 不可抢夺:进程已经获得的资源,在未使用完之前,是不能被强行剥夺的
- 循环等待:若干线程形成了一种头尾相接的循环等待资源关系
二、容器
1.java 的常用容器都有哪些?
常用容器的图录:
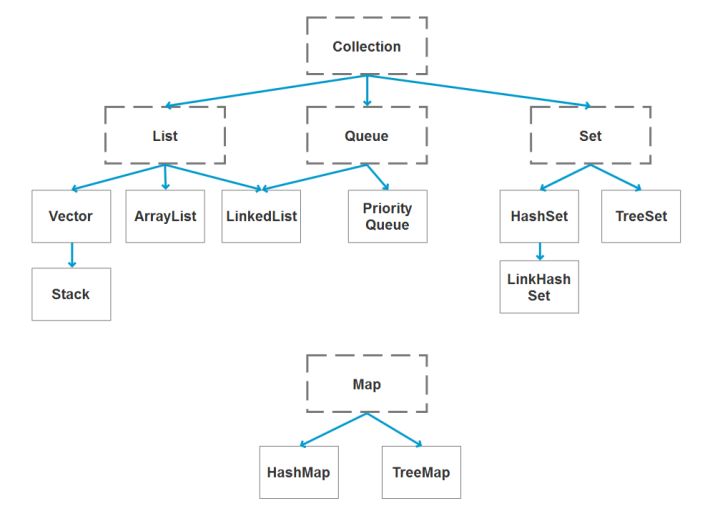
2.Collection 和 Collections 有什么区别?
- java.util.Collection 是一个集合接口。直接继承他的接口有 List 和 Set
- Collections 是一个工具类,提供了一系列静态方法,用于集合中的元素排序,搜索以及线程安全等操作。
3.List、Set、Map之间的区别是什么?
| 比较 | List | Set | Map |
|---|---|---|---|
| 继承接口 | Collection | Collection | |
| 常见实现类 | AbstractList(其常用子类有 ArrayList、LinkedList、Vector) | AbstractMap(其常用子类有 HashSet、LinkedHashSet、TreeSet) | HashMap、HashTable |
| 常见方法 | add()、remove()、clear() get()、contains()、size() | add()、remove()、clear() contains()、size() | put()、get()、remove() clear()、containsKey() containsValue()、KeySet() values()、size() |
| 元素 | 可重复 | 不可重复(用 equals() 判断) | 不可重复 |
| 顺序 | 有序 | 无序(实际上是由 HashCode 决定) | |
| 线程安全 | Vector 线程安全 | HashTable 线程安全 |
4.HashMap 和 HashTable 有什么区别?
- HashMap 去掉了 HashTable 中的 Contains() 方法,但是加上了 ContainsKey()、ContainsValue() 方法。
- HashMap 是同步的(线程安全的),HashTable 是非同步的(线程不安全),所以效率上 HashTable 要高于 HashMap。
- HashMap 允许空键值,而 HashTable 不允许。
三、数据库(sql)
注:本部分sql都已经进行实际测试,所用数据库为 MySQL,如果有用到别的数据库会有红色标注出来。
1.下面有两张表:用户表(Table_User)、考勤表(Table_ATtendance)
| ID | Account | USERNAME |
|---|---|---|
| 1 | liy | 李阳 |
| 2 | zhangxw | 张晓伟 |
| 3 | liuh | 刘华 |
| 4 | yangl | 杨柳 |
| 5 | zhangl | 张丽 |
| ID | User_ID | TIME |
|---|---|---|
| 1 | 2 | 2019-05-04 08:53:24 |
| 2 | 1 | 2019-05-04 08:55:32 |
| 3 | 3 | 2019-05-05 08:20:13 |
| 4 | 2 | 2019-05-05 08:55:33 |
| 5 | 1 | 2019-05-06 08:57:03 |
| 6 | 5 | 2019-05-06 08:52:10 |
| 7 | 4 | 2019-06-01 08:20:14 |
| 8 | 2 | 2019-05-07 08:45:11 |
问题一:请用SQL列出每个用户每个月的出勤率
1 | select a.*,u.USERNAME,CONCAT(ROUND(count(*)/30*100,2),'%') percent from `1-Attendance` a |
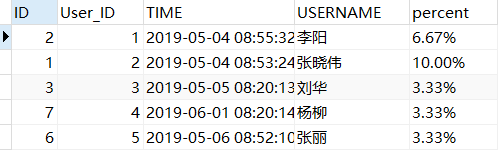
本问题没有什么难点,就是基础的 count() 函数与 group by 分组的应用。
本题运用到的函数:
- **CONCAT()**:用于字符串拼接 CONCAT(str1,str2,str3,…),返回的结果是拼接后的字符串,如果有一个参数是null 则返回
- **ROUND()**:用于处理小数位保留的问题 ROUND(column_name,decimals),第一个参数为要进行处理的字段或者数值,第二个参数为保留的位数。
问题二:请用SQL列出每月出勤的前两名和后两名
1 | select * from ( |
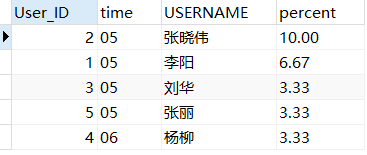
本人认为这个问题还是有点绕的,估计是本人基础太差的问题。而且应该还有更简单的方式解决这个问题,但是我还不知道@~@。请包涵。。。。
这条 SQL 编写的思路为:
使用自连接进行比较,就是分为A、B两个表。加了where后的子查询条件后,就想象成在 A 表后面多了一列count(*) ,bb.percent >= aa.percent,这种比较就是在 A 表中排名越靠前的 count(*) 的值就越小。同理取后两名就是与取前两名相反。
2.下面有两张表:用户表(Table_User)、部门表(Table_Department)
| ID | ACCOUNT | USERNAME | DEPTID |
|---|---|---|---|
| 1 | liy | 李阳 | 1 |
| 2 | zhangxw | 张晓伟 | 2 |
| 3 | liuh | 刘华 | 2 |
| 4 | yangl | 杨柳 | 3 |
| 5 | zhangl | 张丽 | 4 |
| ID | DEPTNAME | PARENTID |
|---|---|---|
| 1 | 环卫处 | null |
| 2 | 考核科 | 1 |
| 3 | 监督科 | 1 |
| 4 | 检查科 | 1 |
| 5 | 接待办 | 3 |
函数参考地址:https://www.cnblogs.com/zhizhao/p/9442799.html
问题一:请用 SQL 列出“环卫处”下属所有部门及各自成员数量
根据问题理解为两种状况:
1)只查询出 “环卫处” 子级部门,就是向下一级。
1 | select p.ID,p.DEPTNAME,c.DEPTNAME,c.PARENTID, |
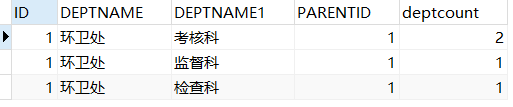
这里就是简单自连接查询,基础语句。
2)查询出 “环卫处” 所有自己部门(需自己创建递归函数)
1 | delimiter // |
1 | select * , |
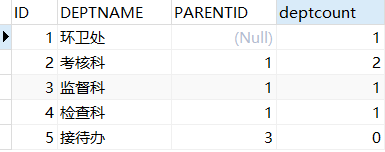
这个问题正常来说第二种状况才是对于本题目正确的理解。
我认为这里的难点在于这个递归函数(其实理解之后你会发现这个函数是真的没什么技术含量的,只不过我平常涉及数据库的还是比较少,所以感觉有点难度,但是理解之后就好了。),其实这个递归函数 copy 走改一改就可以使用,但是如果你想提升自己,以防以后遇到一点都说不上来。还是建议把这个函数理解透。
本题运用到的函数:
**GROUP_CONCAT(column_name)**:多行数据合并
**FIND_IN_SET(param1,param2)**:查询 para2 中包含 param1 的结果,返回 null 或者 记录。详细可查看:https://www.cnblogs.com/lixinjun8080/p/11246632.html
其实理解了函数中的那个查询语句,整个函数也就差不多了。
问题二:请用 SQL 列出“环卫处”下属所有部门中成员数量最多的两个部门
其实这个问题我个人理解也是两种:
1)不考虑并列情况,这种就很简单直接在问题一的基础上增加 order by 排序和 limit 就可以了。所以就不列出此种情况了。
2)考虑并列的情况,我个人认为应该把并列的情况也考虑进去。
1 | select * from ( |
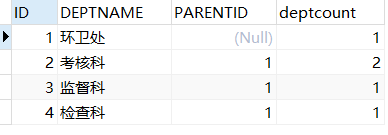
其实这条sql难度也不高,只要你一步一步来就可以了。
大概思路如下:
将 “问题一” 中的查询语句增加分组,排序,并用时用 limit,获取到前两名。
1
2
3
4
5
6select d.* ,
(select count(*) from `2-User` u where u.DEPTID = d.ID) deptcount
from `2-Department` d where FIND_IN_SET(id,`2-getChildList`(1))
GROUP BY deptcount
ORDER BY deptcount desc
LIMIT 2将 1 中查询出来的结果集作为一张临时表查询,使用 group_concat() 函数将 1 中的的人数合并起来。其实就是将前两名的人数查询出来,合并成 2,1 这种形式。
1
2
3
4
5
6
7
8
9select GROUP_CONCAT(deptcount) from
(
select d.* ,
(select count(*) from `2-User` u where u.DEPTID = d.ID) deptcount
from `2-Department` d where FIND_IN_SET(id,`2-getChildList`(1))
GROUP BY deptcount
ORDER BY deptcount desc
LIMIT 2
)a以 “问题一” 中的查询的结果集作为临时表,条件使用 FIND_IN_SET() 函数进行控制。FIND_IN_SET() 函数函数中的参数就是:主表中的人数、和 2 中的语句。到此本问题就结束了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19select * from (
select d.* ,
(select count(*) from `2-User` u where u.DEPTID = d.ID) deptcount
from `2-Department` d where FIND_IN_SET(id,`2-getChildList`(1))
) b
where FIND_IN_SET(
b.deptcount,
(
select GROUP_CONCAT(deptcount) from
(
select d.* ,
(select count(*) from `2-User` u where u.DEPTID = d.ID) deptcount
from `2-Department` d where FIND_IN_SET(id,`2-getChildList`(1))
GROUP BY deptcount
ORDER BY deptcount desc
LIMIT 2
)a
)
)
此处运用到的函数都在 “问题一” 中解释过。如果有疑问就看看 “问题一” 中的解释吧。
未完待续